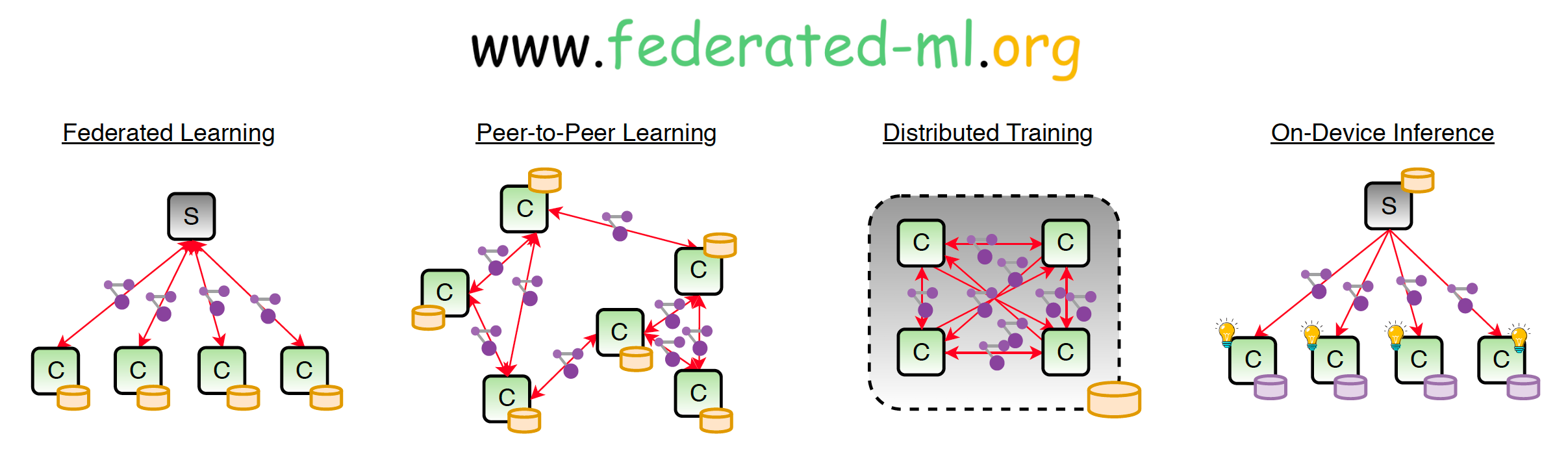
This webpage aims to regroup publications and software produced as part of a project at Fraunhofer HHI on developing new method for federated and efficient deep learning.
Why Neural Network Compression ?
State-of-the-art machine learning models such as deep neural networks are known to work excellently in practice. However, since the training and execution of these models require extensive computational resources, they may not be applicable in communications systems with limited storage capabilities, computational power and energy resources, e.g., smartphones, embedded systems or IoT devices. Our research addresses this problem and focuses on the development of techniques for reducing the complexity and increasing the execution efficiency of deep neural networks.
Why Federated Learning ?
Large deep neural networks are trained on huge data corpora. Therefore, distributed training schemes are becoming increasingly relevant. A major issue in distributed training is the limited communication bandwidth between contributing nodes or prohibitive communication cost in general. In our research we investigate new methods for reducing the communication cost for distributed training. This includes techniques of communication delay and gradient sparsification as well as optimal weight update encoding. Our results show that the upstream communication can be reduced by more than four orders of magnitude without significantly harming the convergence speed.
Software
- DeepCABAC: A universal tool for neural network compression (software)
- Robust and Communication-Efficient Federated Learning from Non-IID Data (software)
- Clustered Federated Learning (software)
Tutorials
- "Recent Advances in Federated Learning for Communication," ITU AI/ML in 5G Challenge, online event, 2020.

- IEEE GLOBECOM 2020 Tutorial on "Distributed Deep Learning: Concepts, Methods & Applications in Wireless Networks", Taipei, Taiwan.

Slides Part 1 Slides Part 2 Slides Part 3 Slides Part 4
- "DeepCABAC: A Universal Compression Algorithm for Deep Neural Networks," 6th Workshop on Energy Efficient Machine Learning and Cognitive Computing, online event, 2020.

- "A Universal Compression Algorithm for Deep Neural Networks," AI for Good Global Summit 2020, Geneva, Switzerland, 2020.

- IEEE ICASSP 2020 Tutorial on "Distributed and Efficient Deep Learning", Barcelona, Spain.

Slides Part 1 Slides Part 2
Publications
Efficient Deep Learning
- . History Dependent Significance Coding for Incremental Neural Network Compression
Proceedings of the IEEE International Conference on Image Processing (ICIP), 3541-3545, 2022
[bibtex] [preprint]
- . Overview of the Neural Network Compression and Representation (NNR) Standard
IEEE Transactions on Circuits and Systems for Video Technology, 32(5):3203-3216, 2022
[bibtex] [preprint]
- . Encoder Optimizations for the NNR Standard on Neural Network Compression
Proceedings of the IEEE International Conference on Image Processing (ICIP), 3522-3526, 2021
[bibtex] [preprint]
- . FantastIC4: A Hardware-Software Co-Design Approach for Efficiently Running 4bit-Compact Multilayer Perceptrons
IEEE Open Journal of Circuits and Systems, 2:407-419, 2021
[bibtex] [preprint]
- . Pruning by Explaining: A Novel Criterion for Deep Neural Network Pruning
Pattern Recognition, 115:107899, 2021
[bibtex] [preprint]
- . Ein internationaler KI-Standard zur Kompression Neuronaler Netze
FKT- Fachzeitschrift für Fernsehen, Film und Elektronische Medien, 33-36, 2021
[bibtex] [preprint]
- . DeepCABAC: A Universal Compression Algorithm for Deep Neural Networks
IEEE Journal of Selected Topics in Signal Processing, 14(4):700-714, 2020
[bibtex] [preprint] [code]
- . Compact and Computationally Efficient Representation of Deep Neural Networks
IEEE Transactions on Neural Networks and Learning Systems, 31(3):772-785, 2020
[bibtex] [preprint]
- . Dithered backprop: A sparse and quantized backpropagation algorithm for more efficient deep neural network training
Proceedings of the CVPR'20 Joint Workshop on Efficient Deep Learning in Computer Vision, 3096-3104, 2020
[bibtex] [preprint]
- . Learning Sparse & Ternary Neural Networks with Entropy-Constrained Trained Ternarization (EC2T)
Proceedings of the CVPR'20 Joint Workshop on Efficient Deep Learning in Computer Vision, 3105-3113, 2020
[bibtex] [preprint]
- . DeepCABAC: A Universal Compression Algorithm for Deep Neural Networks
IEEE Journal of Selected Topics in Signal Processing, 14(4):700-714, 2020
[bibtex] [preprint] [code]
- . Dependent Scalar Quantization for Neural Network Compression
Proceedings of the IEEE International Conference on Image Processing (ICIP), 36-40, 2020
[bibtex] [preprint]
- . Entropy-Constrained Training of Deep Neural Networks
Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), 1-8, 2019
[bibtex] [preprint]
- . Compact and Computationally Efficient Representation of Deep Neural Networks
NIPS Workshop on Compact Deep Neural Network Representation with Industrial Applications (CDNNRIA), 1-8, 2018
[bibtex] [preprint]
Federated Learning
- . Federated Learning in Dentistry: Chances and Challenges
Journal of Dental Research, 101(11):1269-1273, 2022
[bibtex] [preprint]
- . FedAUXfdp: Differentially Private One-Shot Federated Distillation
International Workshop on Trustworthy Federated Learning in Conjunction with IJCAI 2022 (FL-IJCAI'22), 2022
[bibtex] [preprint]
- . Decentral and Incentivized Federated Learning Frameworks: A Systematic Literature Review
IEEE Internet of Things Journal, 2022
[bibtex] [preprint]
- . Adaptive Differential Filters for Fast and Communication-Efficient Federated Learning
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 3366-3375, 2022
[bibtex] [preprint]
- . Reward-Based 1-bit Compressed Federated Distillation on Blockchain
arXiv:2106.14265, 2021
[bibtex] [preprint]
- . FedAUX: Leveraging Unlabeled Auxiliary Data in Federated Learning
IEEE Transactions on Neural Networks and Learning Systems, 2021
[bibtex] [preprint]
- . CFD: Communication-Efficient Federated Distillation via Soft-Label Quantization and Delta Coding
IEEE Transactions on Network Science and Engineering, 9(4):2025-2038, 2022
[bibtex] [preprint]
- . Trends and Advancements in Deep Neural Network Communication
ITU Journal: ICT Discoveries, 3(1), 2020
[bibtex] [preprint]
- . Clustered Federated Learning: Model-Agnostic Distributed Multi-Task Optimization under Privacy Constraints
IEEE Transactions on Neural Networks and Learning Systems, 32(8):3710-3722, 2021
[bibtex] [preprint] [supplement]
- . Robust and Communication-Efficient Federated Learning from Non-IID Data
IEEE Transactions on Neural Networks and Learning Systems, 31(9):3400-3413, 2020
[bibtex] [preprint]
- . DeepCABAC: Plug&Play Compression of Neural Network Weights and Weight Updates
Proceedings of the IEEE International Conference on Image Processing (ICIP), 21-25, 2020
[bibtex] [preprint]
- . Clustered Federated Learning
Proceedings of the NeurIPS'19 Workshop on Federated Learning for Data Privacy and Confidentiality, 1-5, 2019
[bibtex] [preprint]
- . On the Byzantine Robustness of Clustered Federated Learning
Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 8861-8865, 2020
[bibtex] [preprint]
- . Sparse Binary Compression: Towards Distributed Deep Learning with minimal Communication
Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), 1-8, 2019
[bibtex] [preprint]
Contributions to Standardization
- . [NNR] Response to the Call for Proposals on incremental compression of neural networks for multimedia content description and analysis.
ISO/IEC JTC1/SC29/WG4 MPEG2021/m56621, 2021.
- . [NNR] HLS for additional framework support.
ISO/IEC JTC1/SC29/WG4 MPEG2020/m55067, 2020.
- . [NNR] Committee draft cleanups, improvements, and bug fixes.
ISO/IEC JTC1/SC29/WG4 MPEG2020/m55068, 2020.
- . [NNR] CE4 method 19: Results on QP optimizations.
ISO/IEC JTC1/SC29/WG4 MPEG2020/m55073, 2020.
- . [NNR] CE4: Results on parameter optimization for DeepCABAC (method 18) and local scaling adaptation (method 19).
ISO/IEC JTC1/SC29/WG11 MPEG2020/m54395, 2020.
- . [NNR] CE2-CE3: Results on dependent scalar quantization.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m53514, 2020.
- . [NNR] CE3-related: Parameter-Optimization for DeepCABAC.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m53515, 2020.
- . [NNR] CE2: Results on importance-weighted quantization.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m53516, 2020.
- . [NNR] CE2-CE3-related: Local parameter scaling.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m53517, 2020.
- . [NNR] Additional HLS and decoding process specification for Neural Network Compression (ISO/IEC 15938-17).
ISO/IEC JTC1/SC29/WG11 MPEG2020/m53518, 2020.
- . [NNR] Test Data, Evaluation Framework and Results for NNU / Federated Learning Use Cases.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m52375, 2020.
- . [NNR] Basic High-Level Syntax for Neural Network Compression (ISO/IEC 15938-17, i.e. MPEG-7 part 17).
ISO/IEC JTC1/SC29/WG11 MPEG2020/ m52352, 2020.
- . [NNR] CE2-related: Dependent scalar quantization for neural network parameter approximation.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m52358, 2020.
- . Report of CEs results.
ISO/IEC JTC1/SC29/WG11 MPEG2019/m48662, 2019.
- . Proposal of python interfaces for an NNR test model.
ISO/IEC JTC1/SC29/WG11 MPEG2019/M49867, 2019.
- . Response to the Call for Proposals on Neural Network Compression: End-to-end processing pipeline for highly compressible neural networks.
ISO/IEC JTC1/SC29/WG11 MPEG2019/M47698, 2019.
- . Efficient representations of neural networks.
Focus Group on Machine Learning for Future Networks including 5G, no. ML5G-I-102, 2018.
- . Data Formats and Specifications for Efficient Machine Learning in Communications.
Focus Group on Machine Learning for Future Networks including 5G, no. ML5G-I-013, 2017.
|
|
|
|
|
|
|
| |
Proceedings of the IEEE International Conference on Image Processing (ICIP), 3541-3545, 2022
[bibtex] [preprint]
IEEE Transactions on Circuits and Systems for Video Technology, 32(5):3203-3216, 2022
[bibtex] [preprint]
Proceedings of the IEEE International Conference on Image Processing (ICIP), 3522-3526, 2021
[bibtex] [preprint]
IEEE Open Journal of Circuits and Systems, 2:407-419, 2021
[bibtex] [preprint]
Pattern Recognition, 115:107899, 2021
[bibtex] [preprint]
FKT- Fachzeitschrift für Fernsehen, Film und Elektronische Medien, 33-36, 2021
[bibtex] [preprint]
IEEE Journal of Selected Topics in Signal Processing, 14(4):700-714, 2020
[bibtex] [preprint] [code]
IEEE Transactions on Neural Networks and Learning Systems, 31(3):772-785, 2020
[bibtex] [preprint]
Proceedings of the CVPR'20 Joint Workshop on Efficient Deep Learning in Computer Vision, 3096-3104, 2020
[bibtex] [preprint]
Proceedings of the CVPR'20 Joint Workshop on Efficient Deep Learning in Computer Vision, 3105-3113, 2020
[bibtex] [preprint]
IEEE Journal of Selected Topics in Signal Processing, 14(4):700-714, 2020
[bibtex] [preprint] [code]
Proceedings of the IEEE International Conference on Image Processing (ICIP), 36-40, 2020
[bibtex] [preprint]
Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), 1-8, 2019
[bibtex] [preprint]
NIPS Workshop on Compact Deep Neural Network Representation with Industrial Applications (CDNNRIA), 1-8, 2018
[bibtex] [preprint]
Journal of Dental Research, 101(11):1269-1273, 2022
[bibtex] [preprint]
International Workshop on Trustworthy Federated Learning in Conjunction with IJCAI 2022 (FL-IJCAI'22), 2022
[bibtex] [preprint]
IEEE Internet of Things Journal, 2022
[bibtex] [preprint]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 3366-3375, 2022
[bibtex] [preprint]
arXiv:2106.14265, 2021
[bibtex] [preprint]
IEEE Transactions on Neural Networks and Learning Systems, 2021
[bibtex] [preprint]
IEEE Transactions on Network Science and Engineering, 9(4):2025-2038, 2022
[bibtex] [preprint]
ITU Journal: ICT Discoveries, 3(1), 2020
[bibtex] [preprint]
IEEE Transactions on Neural Networks and Learning Systems, 32(8):3710-3722, 2021
[bibtex] [preprint] [supplement]
IEEE Transactions on Neural Networks and Learning Systems, 31(9):3400-3413, 2020
[bibtex] [preprint]
Proceedings of the IEEE International Conference on Image Processing (ICIP), 21-25, 2020
[bibtex] [preprint]
Proceedings of the NeurIPS'19 Workshop on Federated Learning for Data Privacy and Confidentiality, 1-5, 2019
[bibtex] [preprint]
Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 8861-8865, 2020
[bibtex] [preprint]
Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), 1-8, 2019
[bibtex] [preprint]
ISO/IEC JTC1/SC29/WG4 MPEG2021/m56621, 2021.
ISO/IEC JTC1/SC29/WG4 MPEG2020/m55067, 2020.
ISO/IEC JTC1/SC29/WG4 MPEG2020/m55068, 2020.
ISO/IEC JTC1/SC29/WG4 MPEG2020/m55073, 2020.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m54395, 2020.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m53514, 2020.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m53515, 2020.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m53516, 2020.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m53517, 2020.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m53518, 2020.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m52375, 2020.
ISO/IEC JTC1/SC29/WG11 MPEG2020/ m52352, 2020.
ISO/IEC JTC1/SC29/WG11 MPEG2020/m52358, 2020.
ISO/IEC JTC1/SC29/WG11 MPEG2019/m48662, 2019.
ISO/IEC JTC1/SC29/WG11 MPEG2019/M49867, 2019.
ISO/IEC JTC1/SC29/WG11 MPEG2019/M47698, 2019.
Focus Group on Machine Learning for Future Networks including 5G, no. ML5G-I-102, 2018.
Focus Group on Machine Learning for Future Networks including 5G, no. ML5G-I-013, 2017.